Roadmap
Last updated: 20 Jun 2020
Current objectives
File management
[x] Recovery mode
[x] Auto-reloading: detect changes to a shared database and auto-reload
[] Multiple files: file new and file open
[] External .txt files: keep outline synced with an external .txt file
Goodies
[] Control over dropped destination to select at what level of indentation selected elements should have on drop
[] Clickable toolbar
[] Hardware text caret
Upcoming feature list
Recovery mode
As a precaution, Indigrid will display a recovery mode window if it detects that the main window hasn't loaded within 10 seconds on start up.
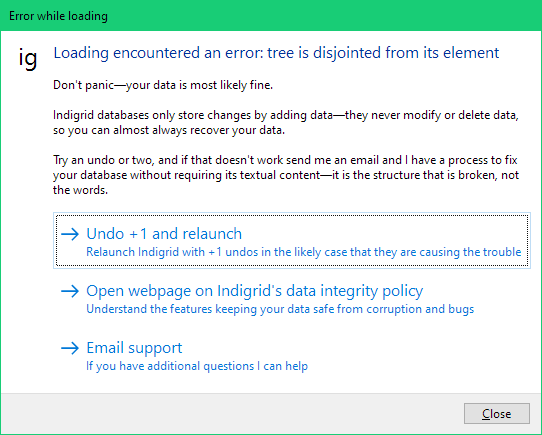
Auto-reloading
This supports having different computers access the same database file either through a network share, or a file syncing service like Dropbox. When Indigrid is running, it will pick up any changes written to the database by another machine, and auto-reload the changes. This isn't robust enough yet to have many people editing at the same time, but more than enough for keeping your changes in sync as you switch between computers.
Multiple files
As more people share with me how they use Indigrid, I'm realizing that I was wrong to not offer file management and that there are good cases for wanting to have a database that is completely separated from another database. I will have to update the design philosophy.
Allowing multiple databases means being able to double click a registered filetype and have it open in a new Indigrid window or to open it via a "file open" command. Saving to the file will still happen automatically, so there won't be a "file save" command. Instead there will be an export command to strip out the history for when you want to send a copy of the database to someone else without them being able to see your past edits, but still be able to use your bookmarks and have the columns and filters how you left them—things that you can't transfer when sending a plain text file.
External .txt files
Since the 1950s when we had process batching and data on punch cards until about the 2010s when cloud applications starting walling off their data: the standard exchange mechanism between programs was via files. Two different programs could operate back and forth using the same file to make changes to the same data. A file format specification was the basic API for programs to interoperate with each other. If a program wanted to allow access to its data, it could either open up its file format, or use an existing format.
I want to do both with Indigrid—release the file format and data access layer as an open source library so that other programs can use columns, bookmarks, and views to compete against Indigrid, without having to rewrite the code needed to do that. And I want to downshift some of the data to make it available for other programs to modify by having the latest version of the outline that you are working on be available as an external text file, so that existing tools that can operate on text files can operate on Indigrid text as well.
Indigrid will sync with an external text file by placing a normal .txt file next to the database that tracks or mirrors the latest version of your data in the database. Indigrid will be able to detect when this text file has been written to by another program and then add those changes automatically into Indigrid as another change to its history—so that you can still decide to undo the external changes. I'm thinking of this as an interface to your data in a format that is easier to manipulate with other tools. As a more approachable way of having access to your data over having to write code against an Indigrid API.
I also like that it makes more transparent where your data lives, and gives you options so that you can collect your text files and take them with you if you find something better.
Why Indigrid will still rely on using a database for storing information
The main reason I use a database over a text file is for reliability.
Indigrid uses SQLite for its database—and a lot of work and testing has been done by the SQLite team on making it resiliant against corruption under many different scenarios and configurations. Text files don't have that same level of resilience—not for years of modifications without a single problem.
The biggest problem with text files is that when you want to modify them, you can't just describe the change you want to make like a database (e.g. "hey database: I want what I previously had, but with the text of element id: 2861 set to: {notes v2}"), instead you have to rewrite the entire file—because the text file format is defined as a unbroken stream of characters: the final form with nothing extra, in the order it will be displayed as.
Which makes maintaining a text file into the computer equivalent of the telephone game. You open the file (this is the part in the telephone game where you are listening to someone whisper a phrase in your ear), make changes to the file, and then write all the file's characters back again (speak it out again to the next listener in the circle).
But all it takes is one well-timed crash—of either the program or the system, or a heat-induced suddenly schizophrenic ram module, or even the more likely—but unintentional—bug in Indigrid's code, to introduce corruption into your text file.
So that is the main reason I have stayed away from using text files as the final central vaults keeping your data safe.
And if that wasn't enough of a reason, there is then also the issue of keeping things that aren't text stored somewhere, like columns, scrollbar positions, what is selected, etc. That all needs to go somewhere too.
Considerations of a new file format
I know that should you lose data with Indigrid, it is kind of game over for your trust in using it—and I've always prioritized data integrity over any other feature.
But what I didn't take into consideration is the prudent distrust of new file formats.
I get it. You wake up some morning to open the Excel file you were working on and it won't open it. Testing you find that Excel will open other files—but this one has some error that Excel gives instead of opening and it isn't like a text file where you can open it and see what data you can extract. In the same way you can survey a damaged book and still recover text from it.
Instead this broken Excel file is like some mysterious tempramental piece of stereo equipment that won't release your cassette tape, and won't play, and so the only thing you can think of is to press different buttons in more and more creative combinations as your anxiously try to detect any sign of life, and it all seems like a futile attempt of guessing the code to an electronic safe.
So how is Indigrid's file format different?
It actually isn't a different file format—it is a SQLite database, which is a file format that has been around since 2001. There are many tools that can read SQLite databases, I like Ralf Junker's SQLiteSpy.
As for the data, Indigrid keeps all versions in the same database. Indigrid selects the version to use based on the value of single row that defines what version number to use. This lets recovery mode undo without displaying anything if it detects that a change is freezing Indigrid due to a bug—you can go back to a previous version and continue instead of having to wait for me to fix the bug.
(But please let me know anyways—I'm grateful for any feedback that helps improve Indigrid, if you are running into an issue, others are probably running into the same issue but haven't reported anything.)
As for the data inside Indigrid: your text is never replaced or deleted—when you delete elements, it just creates a new version with those elements marked as deleted, but you can still go back to when they weren't deleted.
This means that even if there is a bug that Indigrid has that introduces corruption that breaks the current version of your data, Indigrid can still use previous versions because those were untouched.
The database schema has been pretty stable—especially for so early in Indigrid's life. Version 1 of the schema lasted from build 1 to build 17. Version 2 was introduced in build 18 for the bookmarks feature, and persistence of selections, and lasted until now. Version 3 will happen as I split up the database to support the file management features.
You can still take a database from build 1 and build 31 will upgrade it to version 2 and read it—backups are always made when upgrading databases, in case something goes wrong. As of now, there have been no reports of this going wrong.
Progress report
20 Jun 2020: Debugging snapshot generation
I've gotten to the point where it was converting, and loading the database but not showing anything. It turned out that along the migration path I wasn't converting the edges between elements and what tree they are under. And the debugging for this took me a while.
Since there is so much data in the test databases that I'm using, I had to track down ids—reproducability helps here. From those ids, I would print out the handling of the trees at the different stages. But the trees were being converted correctly, just not the edges.
The problem was I wasn't sorting the edges so that when I merge them together with the trees, it wasn't finding them. Finding is a misleading word, it wasn't doing a search for them because that would be slow. More like it is a big merge sort where it advances pointers in all the arrays it is using, and if the pointer isn't on the right element, it won't advance.
Now the database loads up, this took longer that I thought it would. And I don't feel the alleviation that I thought I would. There is still a lot of work to be done.
17 Jun 2020: Sentinels
This is going to be hard to explain, and this problem has existed for a while.
For each page, when you do a refresh, it asks for certain data structures at the version of the snapshot. For some things, like an editor—there may have never been one invoked for that data structure to exist on that page at that snapshot. Instead of having to contemplate the possibility of it not having an editor—or some other type that isn't available—I instead generate an empty data structure that usually is easier to treat than another branch. A default editor for example is all null, and doesn't have the ed_open flag set so it won't do anything. But it won't crash when something is trying to read from it either.
The problem is, where to put these editors on existing database. Do I add them into the database manually? Do I only add them when loading? Do I add them when a page is requested?
I don't have a good answer, but what I do is generate them when you switch to a new page.
The problem is when loading right now, I don't have caches for the new data structures, and searching to the beginning to find nothing, to then generate a sentinel is really slow on debug. So I manually go through each page when loading up and add a sentinel to speed things up. I will throw away this code once I get caches.
But it was also kind of hard to write, because I don't have a good easy method of iterating through all the pages that might be available. So I did that.
16 Jun 2020: Patching ids
I encountered a dilemna with the ids that I didn't foresee. In the beginning ids started from 2, with 1 being the sentinel. But then I changed them to start to create different ranges so I can pick them out faster in the debugger. So snapshots start at 200, views at 300, pages at 400, etc. That way if I see id 428, I know it is probably a page. If I have 228 snapshots then 200 + 228 will be 428, so this scheme doesn't last for very long with real data, but when developing and debugging my databases are usually pretty recent to try things out and it helps. Actually writing this out, I'm not sure I should defend my idea—especially after I write about what happened.
I have a bunch of assert code that assumes the ids coming in a certain order, and these are nice asserts. The program will work no matter what the ids are, they don't have to start anywhere. But the asserts won't work. So I can either change the asserts or the ids—I went with the ids, because I figured the assert code would make it a faster change, since I can use them to guide me if I got the ids right or not.
But it was tedious, when I convert, I have to now patch up all the ids to the new ranges. And some of these ids are hardcoded to mean certain things, like things having to do with bookmarks. So I couldn't just do a SQL update where I add an offset to all the ids.
Maybe I will feel better next time I have to debug something with a bunch of ids to different types, and this helps me tell them apart.
The work wasn't that bad, I just got disconnected from the purpose of it all. It seemed arbitrary. And it is one of those decisions where you don't know how much work it will take upfront to pick your path, e.g. of patching the ids. Versus what the other path would have taken, e.g. updating the assertions.
Knowing what I now know, I would have done the decision the same way. It just wasn't plesant at all. If anything, I would have just organized the ids in the beginning. But I didn't know that in the beginning, why would I have been visualizing so many ids, especially when there were only a few types with ids. I have no lesson here.
14 Jun 2020: Database migration
The previous conversion was missing a lot of work that I didn't foresee. Boring details—my recent life has been trying to get the old data to load in the new system, and when it is finished it will be one of those craftsmanship type of things where ideally no one even notices.
This thing is already at 400 lines of code, and it will only be run once per install and then forgotten about. Nothing difficult, just lots of little details that have to line up correctly. I have this all hidden in db_migrations.cpp so I won't have to look at it.
I'd like to think that future versions won't need as intensive data migrations between versions. I can see how a change of going from one file to multiple files, and also upgrading the undos into their own data types. I have to rebuild the undo streams from just the database records—when I don't have them in memory and compatible with what I am usually used to. Then I convert these undo streams again to use transactions.
During this time I realized that I need a third file for the options of the program, and a history of what files you have opened. And the undo system is flexible enough to allow those into its stream, even if the option changes were made from different files and later they get deleted. I can't tell if the flexibility of the undo system to handle that is a good thing.
I'm worried once this begins wrapping up, that I will still have a lot of bugs preventing the loading from working right, since I've gone so long with so many changes without using real world data.
12 Jun 2020: Database conversion
With all the performance improvements I was making to the loading code, I wanted to get some perf numbers to make some goals of what I can do with the loading.
While there will always be more overhead loading a history database over a plain text file, I can cache the data that is visible on the screen to a special file that I read in first and display, while in the background I get everything else ready. That would feel faster than loading a text file, because it has less data to read to show something on the screen.
If you are using a database, faster loading is one of the advantages you have over a text file and so you should use it. Since I'm in this loading code anyways, I want to take some time and leave it faster than it was before.
But to do that, I need to have some good test data, and right now they are all in the v2 format that we no longer use, and we don't have the conversion written yet. So I'm writing the converter.
I've done this a few times, and it is never fun.
I found that making copies of the structures that you are reading into and converting too makes it easier to later change without breaking the migration code. And also writing the conversions as SQL code lets the conversion run faster and most important, lets you treat the migration code as read-only after it is done. But it is harder to write because you don't have all your data manipulation functions that you are used to once your data is alive in memory.
This went along faster than I expected, even all the details of finding new locations for the files now that there can be many of them wasn't that bad.
9 Jun 2020: Asynchronous loading
Now that each history file has a backing device dependant settings file, I need to change the way I handle loading these files. I already load these files asynchronously to implement timeouts that will kick you into recovery mode. But it is complicated now that there are two files.
So I started to rewrite it all, it wasn't designed for more than one file at a time at all. Not that all this work is just to allow loading two files in at once, I don't even know if that would speed things up.
I'm making improvements all along the way.
And immediately I saw that I didn't need to sort things that were already sorted in the database.
And then I saw that I didn't need to copy from data structure to data structure so many tables of records.
7 Jun 2020: Generic editors
I have pushed the state that the undo system will work on too far, and I don't think undo should extend to resizing a window anymore. But I can't tell where the limits are until I have crossed them.
Clearing a filter to get some context and then undoing to revert the filter is a favorite—because I didn't plan it up front.
I've been extending the undo system to anything that accepts text in Indigrid, including things like search and the upcoming address bar—so that undo isn't siloed inside these editors. And part of making that work is coming up with a generic editor data type that will work with all of them, so that the undo system doesn't need to know the details of each system.
This almost sounds object-oriented, but the implementation is just an editor struct with an additional type and id that refers to the underlying associated type. And there is only one place that does a switch on that type.
A transaction contains operations, an operation can contain an editor, and that editor is associated with the model the editor is modifying. A change to the editor will generate a new model, but when loading it reads the editor and the model, it won't generate a new model based on the editor's state. This takes up more space in the local database, but makes the implementation easier. Later I can revisit that if the sizes get out of hand, but the structures are compact enough that it usually doesn't matter.
5 Jun 2020: Transaction racks
The trickiest operation right now in Indigrid is when you bisect a line. You need to commit the top line as a transaction, but open a tentative transaction on the lower line, because it is in edit mode now. And the function that handles this is really messy, but robust—as if those two ever go together, but in this case they do for some reason. A lot of asserts. But it is a lot of changes.
Anyways, I realized that this whole nested operations deal was great, but in this scenario I actually needed to generate two different transactions, but we are only passed in one tray—what do we do? Nested trays. So now we have a rack that can contain multiple trays.
Right now it is only used in this one function, for the bisect scenario.
But I wrote it like this anyways, just because it cleaned up that function a lot. And maybe someone else will use nested transactions now that they are available.
Usually this is bad tradeoff, complexity that you probably won't ever use. The alternative was pushing down two transactions that the lower levels could fill in, but that would have been more complex. So programming advice: "it depends."
3 Jun 2020: Conversion of old system to use new transaction system
I went through and got all the operations converted to use transactions now.
There is this tension between having state so that you aren't repeating yourself as much, and having no state and passing around a lot of data. Before there was more state, not because it was designed by that in the beginning but because state tends to accumulate as changes happen. The new system is more explicit: easier to read, harder to write—everyone now takes in a tray where it can push its changes, where as before you could always directly interface with the undo system.
As for the new system with trays: the analogy of how this works that I came up with is that when you start a transaction, you are given a tray. You ask the transaction system for a new tray, and internally it locks everything until you discard or commit the tray.
What is in the tray isn't visible to anyone that doesn't have the tray, until it is committed, giving isolation. As data structures are created, you append them to the tray.
Already the new system addressed a kludge in the previous system of cancelling edits on an element. Before there were some one-off flags to handle this scenario. The new design handles this gracefully by letting you commit the current tray with the changes you know you are going to discard—in case of a later undo—and then add another transaction with the changes before you entered edit mode. This way, when you undo, you go back to the changes you you discarded. If you undo enough, you will go to changes before the edit mode changes you discarded. And it lets you redo back all the way to when you discarded your changes and are back to the changes before the edit. As far as the undo system v3 is concerned, it is just assigning the pointer to the current version you want.
I don't even remember how I handled this before, but it was messy because you had to have flags that would go outside of the undo stream to make this work because you couldn't have the same edit appear twice in the same undo stream because the change and its undo history were tied together. They are separate in the undo system v3.
Which also means that I can remove transaction flags out of the model structures—snapshots—themselves, into the transaction structures.
Snapshots are immutable, except for a flag to mark if it has been saved to the database or not. I kept it in the snapshot structure, and then I had to make it atomic because snapshots get passed around a lot to different threads. But that was the wrong place to keep those flags, and then each structure that is persisted needs its own saved flag. After lifting this flag to the transaction level, it makes more sense. And I got to remove the atomic from snapshots and now after initializing them with flags, they don't change. So they are easy to work with across threads.
Things are falling into place. I like how after writing something incorrectly, your new design seems to address issues that you weren't consciously aware of, like the cancel changes in edit mode problem. And then eventually you forget the reasons why you did things—I hope this helps someone else out.
26 May 2020: Persistence to split files
Operations come in two flavors depending on whether you are in edit mode or not when the operation occurred. This way we can easily drop operations if you hit escape while in edit mode.
I have these operations diverted in two files now, the edit mode changes go into the local file, and normal mode changes go to the history file.
This sounds easy, but I had the one database assumption in a lot of little places.
When I'm doing this kind of work, I find all these things that I want to clean up but I don't want to just be cleaning up code because that isn't progress that people care about, they want releases, new features. But after a while if I don't refactor—then it starts to become difficult to live with myself, all day I'm seeing how once clear distinctions become out of date and vague and obscure. But it isn't any one little thing that would make a big difference.
I log these thoughts out as I see them, so that I can get back to the task at hand, and to give me something easy to do in the evening when I'm tired, as kind of a reward. The difficult exploration of code that has to change in the morning, and a list of little changes as busywork in the evening. With music. It is working for me.
23 May 2020: Persistence of editors
I added the code to save and load editors. This is a crazy table, at 20 columns—the record holder. But all but one are just numbers, so 76 bytes overhead + the text.
This means that you can leave an editor open in a bookmark, and then jump to another bookmark and when you come back, your caret will be where you left it.
The editor itself can reference different types, and I made that a variant—but I regretted that choice for persistence. It is on my list to take it out, and just use a type enum. Plus anything to bring down the compile times.
22 May 2020: Persistence of operation transactions
I need to adapt all my operations to declare what new data to the database they have generated, and wrap each operation up in a transaction. I could have modified my old design to work with transactions: it would have meant less changes, and less total lines of code but I wanted to make explicit what was invisible before, because with nested functions it was hard to tell what might or might not add data.
But in the meanwhile, without an operation being wrapped in a transaction, any data it generated would no longer be visible to others. And I don't want to modify every operation until I understand the spectrum of ways that this design would impact existing code.
And so I have been trying to get the minimum amount of work needed to get it running again and testing it out—so I can be confident that my design is ready to be applied one by one to all the operations.
A big milestone reached today is that transactions are persisted to the history and local databases, and I've rewritten enough operations to use the transactions that I can load Indigrid again. I still can't add any new elements, but I can see how the different areas would work under the new transactions and I think my current design will work. Now I just need to port them all over, and go back and address all the debt that I've accumulated, with comments in the code of areas that need to be addressed.
19 May 2020: Undo system v3's operation transactions
Everything is broken right now, and I can't even load data anymore because I changed the database schema but haven't written the code to write out using this new schema. In the meanwhile I have to recreate new blank databases when doing any testing. Which I'm not doing much of right now, because it is mostly translating things from the old system, into the new transaction system.
Indigrid has been a couple of weeks without being ready enough to test it—these are always risky builds once they come back to life. Usually with a lot of bugs—the kind that affect many areas at once in mysterious ways, so it looks like more bugs than there actually is. It can be discouraging when so much is broken at once, and then you fix a couple of bugs and it gets immediately much better.
And I'm optimistic, because the new undo design is looking pretty good.
The database schema has changed to v3 to support multiple files. That exposed some additional requirements that the undo system needs. And since this requires modifying the undo system, and the undo system needs to be rewritten—the undo system has changed to v3 as well.
A problem with saving undos—that became very apparent after writing undo system v2—is that undo information isn't a separate table, instead it is reconstructed from the actual model and view changes into the original timeline. This is way harder than defining the timeline as operations happen—when you have all the information—and storing that timeline. That is what undo system v3 addressed.
A history of Indigrid's undo systems
Undo system v1
In the beginning there were two data types that Indigrid used to save your data: snapshots for model changes, and views for view changes. And the undo system managed both of them, because there were only two types. And view changes—say collapsing or scrolling—could be updated without going through the pipeline that flattens out the dag. At the time, the novelty was in saving view changes so that you can undo them.
Later build 18 added the ability to persist what was selected in a column, and the undo system v1 was updated to handle another data type—no biggie.
Undo system v2
I wrote a custom textbox/edit control in build 21. Before that when entering edit mode I would carefully position a Windows edit control over the normal mode text—in the same way that File Explorer puts an edit control over the filename when you rename a file. Using a Windows edit control was a bad idea that ended up taking up more effort than a custom edit control, but I started with that because I was intimidated by the thought of recreating an edit control's functionality. It felt like a lot more work than it actually was, but that is another story.
As part of writing a custom edit control, I had to handle its internal undo state—the Ctrl + Z actions inside the edit control. This took less than a day as I didn't persist that undo data, and I organized all the editor's state into a single struct that I would overwrite on undo. Using an array of those editor state structs, undo could clobber the current state with the previous struct. Since this detailed word level undo data would only be kept around for the lifetime of the edit control, it didn't need to get clever about how it stored things.
And now with my own edit control, I saw an opportunity: as I now had access to the embedded edit control's undo information—that meant I could jump inside the edit control and skip through those word by word changes even after you commit your changes to an element with Ctrl + Enter. Before, after you commited changes, undo would take you back to the next model change—the change before you entered edit mode.
To recap: you had an embedded undo stream when you were inside edit mode, which was the embedded edit control's array of editor states. And when you would commit, that embedded edit control went away and took its undos with it. Undos wouldn't break out of their containers if you were in edit mode—undoing until the beginning would take you to the original text inside the embedded edit control, but it wouldn't pull you out of edit mode to the previous edit. You had to be in normal mode for the undo command to flip through the model and view changes you've made. And in edit mode, you couldn't do normal mode operations without me specifically writing code to make that work by interleaving the actions: so indent would work in edit mode after a lot of written code, but you couldn't open a new column in edit mode because I didn't support that.
Enter the undo system v2 which would delegate the undo action to either the embedded edit control in edit mode, or to the main application if the edit control is already at the end of its undo stream. Making it feel more like one big text editor. Then I realized that I could also interleave normal mode operations while in edit mode now.
Writing the undo system v2 was the hardest thing I worked on Indigrid. And the result wasn't some hard-won stable design. It was a good enough design that I knew I would have to rewrite the moment anyone so much as to opened the file it was contained it. It had corner cases that I couldn't fix without upsetting something else, and broke my confidence in me as a programmer more than anything else that year.
How did it go so wrong? I had two different—but proven—undo systems, why was having a manager that decided who should undo so complicated?
I underestimated that this would even be a problem—this seemed like just an if statement in front of which of the two undo systems to delegate the command to. As I went, it was always just a little extra work to get what I had to expand a little to fit in what I was currently working on. The main objective was a custom edit control, not the undo system. Since the other two systems were simple and robust, I was pretty loose in implementing this. I thought I had undo systems down.
In the beginning this system was fine when you couldn't have a model or view change—an action that went into the undo system v1's stream—while you were in edit mode. Once I allowed those operations to be interleaved, then it got complicated in figuring out who had the last undo.
After that, the technical reason why it was hard for me to write, is there was no centralized stream that matched the undo data of these two different systems into one linear timeline. Instead I would reconstruct what undo should be next after the fact, when I have already lost a lot of information—most importantly the order. So I was reverse engineering how the code might have constructed those actions and in what order based on their final composited change.
I couldn't get away from the original design when in retrospect it was a fundamentally flawed design from the beginning.
I kept this version because it was better than the versions it was replacing, and improving the corner cases never seemed important enough based on other things I could be working on. No one ever reported them, and from testing I found undo errors in Word—as part of seeing what the standard was—so it seemed like an unimportant problem. But in the back of my mind, I knew how I wanted to write it. The most important thing was to have a central authority of undo actions registered as they happened.
This happens. I took the right approach when writing it, but the results were bad and so it seems like I should have known better—but the thinking behind it was acceptable. If you approach things by writing the straight forward code that will handle it, and you allow things to get to a certain level of heavy use before you feel you have enough context to come up with a solution that would address the constraints—then most of the time things won't need any additional design and you would have saved a lot of time in implementation.
And then in the cases like this, you become aware of the constraints that prevent your straight forward approach from being adequate, which you can use when rewriting.
Undo system v3
After sketching out enough code to understand how multiple files would work, I discovered some additional constraints that the undo would need. I kept working on the harder parts, the parts I wasn't sure about and that represented risk to unearth the complexities I would need to confront.
- It had to be distributed amongst two files: a history database, and a local settings database—and it had to work even if the local settings database was missing (because you are on another machine and local settings are per device).
- It had to allow for any type of state (including state not thought up yet) that the system can have—to the point where you can be typing and have the application restart mid-keystroke and you wouldn't notice, because all the state that Indigrid creates can be written out and reloaded on restart.
- It had to allow for disjointed undos operating upon different undo streams depending on what context the undo is coming from: per file, per window, per bookmark, per column, per parent, etc.
- It had to allow for nested operations—the ability to make changes that depend on each other but that aren't visible to the rest of the system until all the changes are ready, after which the system sees the final result of those changes all at once. This is a requirement if different parts of the program are to make changes concurrently, and allows for more natural groupings in the undo stream so that undo isn't too detailed with steps that you aren't interested in.
The design of undo system v3
When I only had two different types of data as the first undo system had, it was hard to see patterns—I just treated each stream differently. But by now—after having experimented with some of the planned features I want to write that I imagined would have the most difficult state to persist—it is easier to see the patterns. And undo system v3 is the result of that.
Any time the pixels change, a refresh is done of the window and everything is drawn again—that could be optimized even more, but this whole process is fast enough because there is only one pipeline and optimizations to it affect everything because no one directly manipulates the pixels. The window draws what the data is, instead of usual UI programming that directly modifies the state of UI objects, and those objects keep their state. So undo in that situation means figuring out who has what state, and how to reset it back to what it previously was.
Instead in version 3: you add your data to the ledger, you commit the transaction, and a refresh recreates everything using the latest data. It gets this data by asking the undo system what version of data you are on. And undo just changes that version, no data is moved.
Version 3 is simplier than even the first version, because now the pipeline is fast enough that it can refresh everything within a few ms, we don't need to optimize for more gains by skipping things to refresh on an undo—like we did in v1.
And it allows for any type of change, as long as it has an id. It can be a delta based struct, where the changes depend on the previous changes like views and snapshots, or it can be clobber based struct, where the struct contains all the state you need to recreate it—like editors and selections.
12 May 2020: (Roadmap meta)
I don't remember where I left off, but I stopped writing about my progress because I felt that it was becoming a surrogate for actually releasing. Was I selecting to work on increments of concrete progress that could be easily written about?—Instead of wandering into the surrealist tangles of complexity where I knew most of the risk lies because it doesn't make for good writing? (E.g. "day 17... still don't know what I'm doing.") I was worried about that, and so I tried not writing as I pierced these cell bodies all at once to see how I was going to put everything back together again.
Are you really working on something if you can't articulate what you are working on? Or could those be the best sessions?
These were months of confusion, and instead of holding on to the driftwood of stable features and incremental progress—I used the confusion to seek out and uncover all the places that I didn't want to work on because they were too heavy. I used that resistance to figure out where the shadows were—because without dissolving those unknowns, they represented too much risk—I didn't know what was in the shadows, and I didn't know how things would have to change once I decided to confront the them.
Where I am currently at is I tried introducing complex and risky features in all at once, just enough of them to begin to see why the problem is difficult. If I see the complications laid out in front of me, I can get enough of the details consumed so that my unconscious can order them, and come up with a design that addresses most of them. If I try to do this concretely step by step, my worry is that while progress would appear more steady, I wouldn't be able to get the seams to line up in the end. Because it will take me a long time to see where I am going, because I'm taking my time in getting there.
So that is what I did, I tried to make a lot of progress all at once—gladly taking the technical debt—because I didn't know where I was going yet. And that is what has happened, because I never foresaw that introducing multiple files would require me rewriting the undo system. Twice.
But it is easier to rewrite something when you have discovered the right requirements, than it is to come up with the requirements in the first place, so this is a great trade off.
Now I get to throw out most of the temporary code that I have written, because I know now where I am going. I don't think I would have had the confidence before to approach it that way, I would have been too protective of all the code that I have written. I'm not sure when I started looking at code differently. I know that John Carmack continously rewrites his game engines—I suspect he is trying new things when he gets ideas on the parts that weren't the best on the previous version, and also keeping the ideas that worked well in the previous version. Before I thought of code as a novel that you can keep continously adding to, to make more epic. Reusing code. Always building up higher and higher. But now—I see code as a liability, and I rewrite things all the time when I realize that the requirements have changed.
23 Jan 2020: Multiple windows (feature)
The past week I have been in the zone, and way more productive than usual. And I've been writing and logging all the habits that I currently have going for me because I've been productive like this before, but then I forgot the routines that I had that kept me productive. But this is good news.
If I want to auto-reload the database, I need to make a distinction between what settings from the database apply to the machine
After the database auto-reloads, there is a problem—the window settings also get transferred. This is a great feature if all your machines have the same monitors and resolutions, else it is awkward because on re-load it will want to position the window to where you last had it.
Since I need to go into the code that handles windows anyways, I thought I would unlock the multiple windows feature that just needed a little bit of polishing to be ready. Before I released build 1, I had many features sketched out but that I then disabled to keep the quality high. It takes a lot of effort to really lock down a feature and make it good.
Getting windows working was straight forward. The only subtleties were having the notifications propagate across windows—before it assumed one window. And the distinction between actually opening a window at the platform level, and packaging that information as an operation. The update model right now is to start afresh on each change, like a render pass. Whereas changes to the window need to mutate state at the platform level. That was messy.
1 Jan 2020: Build 29, fixing the brickable bug
The original bug came down to one line. Instead of checking if an element is a parent using elements in the column, check parents outside of the column as well. But I didn't start there, I started from protecting the database from ever having cycles be introduced.
The first layer fix took 40 changed lines, and 60 new lines: checking for cycles, reporting the error, and preventing redundant checks for performance.
The second layer fix was to show an error in case a cycle was detected when trying to display a column. The database actually handles cycles OK, it is displaying them that freezes.
In the original bug report email, they mentioned that they had tried for over 30 minutes to find a solution by searching the web and figuring it out on their own, and they were just asking for a way to manually undo a change to the database since Indigrid would no longer load it. If I have an error message—while not ideal—it could at least give clues so they can google for something relevant. Distinguishing freezes because of different root causes via searching is hard: "Indigrid is freezing, why?" But searching for something like "max tree depth of 111 hit" while cryptic, is better at getting back relevant search results.
And the final layer was a single line change so that dropping doesn't even attempt to add a change that would create a cycle.
31 Dec 2019: Brickable bug reported
I had a user report that they couldn't open their database—that it would freeze on loading. They sent their database over and it contained a cycle—where an element contains a path to itself as a child element, so when Indigrid processes it to try to display it and its children, it will never finish finding child elements under it: thus freezing.
It was easy enough to manually undo the changes and send back a fixed database within a couple of hours of the first email. I felt better after unblocking them, but was worried about what caused it and if was affecting others.
I had to find a way of reproducing the bug—the first step of debugging. Else how can you verify afterwards that your fix works? Sometimes you can't find a way of reproducing the bug reliably, so you introduce logging to give you hints in case it happens again.
My hypothesis was that there was an operation that was allowing a cycle to be created. While this type of bug should have never happened, what was more unusual is that it got into the database. That means that first I'm creating a bad change—which is a bug on its own—but it is a separate and bigger bug to then take that change and make it permanent by writing it to the database. So there were at least two problems that had to line up for this to happen.
Looking at the resulting database though only gave me what has happened, not how it happened.
Indigrid tries not to make a cycle, and I verified that changing parents had checks to prevent cycles. Changing parents is the suspect code of introducting a cycle.
Then I found I could reproduce the bug. There was a way to fool the checks. It gets technical fast. You had to have two columns, where the header of one column was the child of the element you were dragging in from another column. Now dropping a parent element into the a child element's column is obviously wrong and the checks would prevent that when updating your drag to show you where the elements would go if you let go of the mouse button. But there was a bug in when you let go of the mouse—it would use where you let go to drop if you hadn't dragged over any valid drop targets. That means if in the path to drag over this child column, you passed by any valid target, then dropping wouldn't do anything. But if you were careful and made a path without touching anything else, it would get confused about there being no target and try to calculate the target. Only on this calcuation, if it couldn't find the parent from the current column, it would assume that it was OK. But it wasn't OK. So it didn't look like you could drop there—the interface wasn't showing that it was a valid drop target, but if you dropped anyways—it would incorrectly let you.
This was bad. And the scary thing is that this bug has been around since the first version, and no one had reported it until now.
25 Dec 2019: Planning
After working so long on the hardware acceleration code and then releasing a version without actually having the OpenGL enabled in it seems like a wasted effort—I may as well wrap up the OpenGL branch. But thinking about it over a few days I realized that it was good enough right now because of all the performance gains I got with GDI. And there is still a card up my sleeve to increase my GDI performance by another significant percentage—having the menu messes up my painting and I have to triple buffer the painting to avoid flashing. Once I draw my own menu I can go back to double buffering. The latencies of a full redraw are low enough for most monitor refresh rates, so I would only be helping people on the really low end, or people with 4K+ monitors.
The original goal was to improve performance enough to have drag and drop feel more responsive. Then from the numbers that morphed into dropping GDI for OpenGL for speed—which also presented the opportunity of reducing the surface area that I would have to port to other platforms, since OpenGL works on more platforms. So now there are two objectives: speed and portability.
I rearchitected the drawing code to go through swappable rendering technologies—so I could use both to compare the results. Only in doing that I sorted my drawing primitives and batched them, and turns out that speeds up GDI as well. But I didn't notice immediately that I had already achieved the original goal, because now the goal was focused on doing what is necessary to get OpenGL working.
And the biggest problem with OpenGL on Windows is that the font rendering doesn't match what is native to Windows. This won't matter in 10 years when monitors have better pixel densities, but in the meanwhile it looks off in Windows. Ideally I'd go through a DirectX path on Windows so that I can use DirectWrite for handling the font rendering.
Planning can be so boring because there is no action happening. And it hurts to not wrap up something completely, it is still nagging at me what I left incomplete.
Only the original goal has been met, and from this point to continue to work on the OpenGL code is another feature. And looking at the delta from now to a completed OpenGL renderer—that isn't important enough to go ahead of other work that is on the backlog. So I'm shelving the OpenGL work for now.
22 Dec 2019: Maintenance build 28
The longer I go without releasing, the harder it is to use the entropied muscles needed to lock it all down enough to release. Two months between a release is enough to feel the effects of being out of shape and the effort demanded of you is more as two months is plently of time to make enough changes to complicate the delicate verification process done before releasing.
And if there wasn't a rush to fix the growing list of reported bugs I would have spent another month finializing the OpenGL rendering code. But I cut it short to get to a point where I could release a version that is better than the previous version performance wise, that I could base the fixes off of.
Fixing bugs is easier than releasing features, and this fast release was just fixing up some of the bugs reported between October and December. Nothing reported during that time was urgent, so it was more efficient to apply them to the feature branch.
16 Dec 2019: Feature build 27
Over the past week I have been using the latest version in my writing and it has been solid. The reduced latency between a keystroke and an action is noticable, I can feel the results of all that performance work even in just typing. I didn't think I would. And then of course things that were slow in build 26 like dragging are night and day smoother now.
The rest was fixing tiny little bugs I don't know if I even want to mention—things that I introduced into build 27 because of the new renderer. I had a hard to track string formatting bug coming from new newly written string formatting library—I had a calculation inside a debug portion and wasn't getting called in the release version. This is such a rookie mistake I don't think it occured to me that I could make it. So I was looking at the optimized code generated looking for differences. And then oh yeah, this release version is doing something that the debug version isn't. It has been a while since I've had to debug a release version.
A bunch of other things like that. The hardest thing was getting the glyphs for expanding and collapsing to align themselves correctly down to the pixel with all these new layers of generating primitives with the new renderer.
This version becomes build 27, I still have a list of bugs that I want to get fixed for another maintenance build before continuing the hardware acceleration work. But I'm releasing this as is because it is already such an improvement over build 26.
4 Dec 2019: GDI handle leak (bug fix)
While testing Indigrid with my own writing I found that it would crash after a while, around the same time—which is why I like to test it before releasing it as a beta. Leaking GDI handles is different than memory in that there is a really low limit—but that might be a good thing since you shouldn't need so many GDI handles.
The code was failing after a while, so it required me to type about 3,000 characters before it happened—so these types of bugs I spend more time with thought experiments than with verifying a reproduction, because my reproduction takes so long—and I wasn't too sure about it being reproducable.
First round I traced it to invalid drawing dimensions. Second round was a dead-end—I just change the way I calculate drawing dimensions by caching, so I thought that was wrong—but it wasn't. Third round I found the dimensions were bad because the DC was null—this was kind of a lucky thing I noticed that stood out to me because Windows doesn't complain about using a null DC and I've never seen a null DC before.
Then reading the docs about what would cause a null DC, and calling GetLastError, and it giving me nothing useful—it should have at this point told me I've exhausted my GDI objects, but it didn't and I didn't see that connection yet—I thought sometimes creating a DC would fail and I had to prepare for that. I had changed the way that I create DCs with memory backed DCs—which is only temporary anyways until I draw the title bar myself. In the meanwhile this is all a workaround so that the menu bar doesn't flash because it doesn't play nice with WS_EX_COMPOSITED. Programming.
Anyways, on the fourth round I found that the null DC came from another part of the code, so then I suspected a GDI leak. Things like that: if you don't know that GDI exhaustion is a thing, how do you know if it is a problem if GetLastError doesn't let you know? I only know through experience, I open Process Explorer and find the GDI objects count and sure enough I'm at 9,999. Now I have a meter I can check, and I realize I'm leaking 3 GDI objects per keystroke. I binary search all my GDI object creation calls and it was a null region I was creating and not destroying.
I also made recalculating layouts faster by clipping the output, even though it is already to memory and not tied to going to any actual device—I can see why GDI wouldn't know that and not be lazy about setting pixels as you give it GDI commands. I wasn't doing the clipping consistently everywhere, and realized that as I checked around to make sure I wasn't leaking a region object anywhere else.
And a couple of other bug fixes, they are fast to implement now that everything else is shaping up.
3 Dec 2019: Untangling global variables (infrastructure)
My strategy for global variables is I like them, I use them—I'd rather not inject them into everything if it is going to be global anyways. But I try to keep them all inside a single big structure so I can easily grep their usage. Sometimes it is nice to know that changing something directly will be reflected everywhere, and that you don't have to worry about propogating a copy down everywhere.
As I work, sometimes something begins as a static to the file variable that I then want to extern. And now I wanted to fold those occurrences back into the master global variable. Only this time there is a divide, because some of the globals are tied to the platform. So I structured that and actually got to keep the globals platform-independent, and in the core library.
Nothing exciting, and Indigrid works the same. But now Indigrid only has 3 global variables. The master one: which has all the options and settings, the commands table: which I like having in its own file so I can send out for translations, and one for profiling which I guess makes it easier to compile out in non-perf builds.
2 Dec 2019: Core library (infrastructure)
I didn't want to work on this right now, but Visual Studio was giving me red squiggles everywhere and slowing down everything. I tried just to disable the entire thing but it after disabling all the options I could find that seemed relevant it didn't do anything to reverse that tide.
Then I had the hunch that it had something to do with the core library and that if I rebuilt it, Intellisense would be satisfied. No idea why it had a problem all of a sudden, I haden't built this project in a while and nothing I was using was depending on it.
I have a core project where the majority of the code lives so that it can move from platform to platform, the server project uses it to do Indigrid things, and the main application uses it—but not as a library but just includes those same files into its own project so that it can have it statically linked. This won't be forever but in the meanwhile not having an extra dll is nice.
So it was just adjusting the pre-compiled header and project settings to build something and since I was already looking into it, I might as well fix it up enough so that someone could dynamically link to it if they wanted.
Working with projects, trying to get code that would compile and link in another project but not in this project—adjusting your include directories. It feels like installing a stove when you are interested in cooking. But these things come up, so you have to know about stoves too.
It wasn't that bad. And it fixed Intellisense.
29 Nov 2019: Refactoring toolbars (infrastructure)
The toolbars—one for normal mode, one for edit mode—are built from a single table that describes all commands in Indigrid. A single structure defines a command, its text, its shortcut, and where it should appear in the program: top-level menu, context menu, and/or toolbar. Keeping all of this in one place—each on one line—makes it easy to assign different shortcuts and for changing the language of the interface—all planned features that aren't currently implemented.
But ideally the toolbars shouldn't be built from the master commands table, they should be defined on startup. And while I was at it I would divide the concepts up because right now they are dependent on the platform, so now there are commands, and toolbar_buttons, and a command id table that isn't tied to the platform, which was tended and pruned.
Now it seems reasonable, but at the time coming up with names for things that are so similiar and to not get them confused. It wasn't the most motivating things to work on.
I also fixed two bugs: the title bar wasn't updating to show what column you were in. And collapsing while in edit mode would incorrectly move the focus up a level.
26 Nov 2019: Lifting the limitation of modifications clearing cut elements (bug fix)
I've steered the ship back enough for a quick fixing of an accumulated list of reported bugs. So I can get some goodness released soon and then go back to focusing on getting the features the rendering performance work now enables.
As part of wrangling the code into two camps—the code that multiple platforms can share, and the code that depends on the platform I disabled the clipboard as it was cutting across both camps. Instead I treat the clipboard as state that is passed into the platform-independent code.
While doing that I noticed I could lift a limitation with cutting, before if you cut some elements it wouldn't remove them yet, instead marking them as "cut" so that you can perform a move—like in Excel. But if you made any edit, that would "uncut" the previously cut elements. Instead I wanted it to work like File Explorer, where you can cut some files—and they don't move yet—make some changes like creating a new folder and then decide to paste inside the new folder and it would work.
There are little corner cases in doing that, like cutting elements and then deleting them, and then trying to paste. File Explorer will give you an error as it tries to move something it can no longer find. Indigrid just filters out those elements when you go to paste.
And like most features, most of the work is spent on the smallest of details, in this case defining what the selection should be if you cut some elements, then delete some of those cut elements, and then paste those elements, and then you do an undo.
The undo of the model is standarized and untouched—but the view's selection needs to be defined when you paste in case of undo and at that point you can't take the current selection because it is not on what you want to paste but where you want to paste—it has no relation to what the original selection was. And I can't just use the selection at the point that the cut was invoked, because the focused element could have been deleted.
I already have a function that will patch up a selection to move the focused to the closest element—but I needed to modify this to work with past selections, the hard part being that I need to reconstruct the visual order, which is different than the in-memory representation that isn't visual but rather a set of deltas to keep the size of the changes small.
90% of the work was on the off-chance that you cut some elements, then delete some—but not all—of them, paste, and then undo: a selection is created so that you can see the now filtered list of elements that were cut. Details that no one will notice if you do everything right. And those are the best type of features because you don't have to do anything to benefit from them.
22 Nov 2019: GDI drawing (bug fixes)
Z-order: since OpenGL supports z-order but GDI doesn't and my generic rendering code now assumes it, I needed to reimplement this in GDI. There were a bunch of efficient ways I was overwhelmed with choosing when writing this but I did the simplest thing I could think of first. I kept the z-order values in a tight range and discrete so I could do a stable radix sort on them, and broke up my existing render_commands function to take in a vector of commands. This involves lots of copying. And yet it was good enough, didn't increase the times enough to show up on the profiling so I left it like that.
Working from perf data doesn't just make the application faster, because you build intuition of how long things should take—it makes writing code for it faster because you can write things that "feel" slow and then have the numbers prove you wrong, and you can leave it like that. Instead of writing more lines of technical liability.
Kerning gaps on filtered elements: even though I have my own text measuring function, the renderer still has code that assumes it works like the Windows text measuring function which it will repeated call because it doesn't have a cache of the widths. From there it chops up text as separate draw calls if any of the text attributes change. If that slice happened between a pair of letters with kerning on them, the widths would drift apart and you would lose the kerning. I just had to rework the measuring. While I was doing this I made the text render command struct wayyy smaller as it now just has pointers to the text attributes instead of an entire vector of them. So fixing this bug also made the whole thing faster just by giving it another revision pass.
Edit mode had an off-by-one error that messed up where the caret is in relation to the characters because it through it was on the next line, but visually it all looked really mysterious—lines weren't drawn right, text didn't seem to wrap at the right place, and I couldn't tell where the caret was getting its positions from. Bugs like these: when it seems like many things are messed up at once and it just comes down to one thing—they should have a name. And then bugs where one thing seems wrong but it is the result of an interaction of bugs and takes a deceptively long time to work through—those should have a name too.
I'd call the first class of bugs, rubrik bugs because a couple of twists when you are close to solving a rubrik's cube turns it from jumbled to solved—and it is also easy to determine that it is solved.
And I'd call the second class lemon bugs because it is like a car you take in for one thing—followed by a quick montage of four things within four weeks—and still not fixed, you are just revealing how hurt the car is—and once it is fixed, you are skeptical for a while.
18 Nov 2019: GDI dragging (performance)
The two operations used the most in Indigrid is:
1. refreshes, i.e. converting changes—deltas against the last snapshot—into data that can be displayed. This is an involved update process that Indigrid will run through on any change, to keep the logic consistent between changing data, and updating all the caches needed to display that data efficiently.
2. rendering, i.e. drawing changes—taking the cache created from the update process and converting it into the primitives that the video card needs to display pixels onto the screen.
Most of the changes have been to rendering (2), but I made some performance fixes to refreshes (1). The refreshes are what makes dragging sluggish because it asks for so many of them while it is dragging.
I addressed the refreshes while dragging in two ways. First I would generate less refreshes, and second I made the refreshes faster.
When you drag, it does the refreshes in the background on separate threads and will then communicate those calculations back with the ui thread via notifications. But these could come in out of order and if that happened it would appear that your dragging "jumped" back to the last notification that came in. I fixed that by only rendering a refresh's snapshot that comes in if it matches the last one asked for—if it isn't then it discards it without rendering knowing that there is still another refresh notification pending that will come in. And I also would have the calculation threads check every once and a while to see if they should cancel their progress if they can detect that they will be thrown away. But not too often, the more you check if you should be working, the less work you get accomplished because you are too busy checking if you should continue or not.
As for the speed of each refresh, they were already pretty optimized because in the beginning they weren't fast enough at all for convincing dragging. But after giving them a second look and trying different ideas, I found two good optimizations.
The first was at a higher level in _bk_lys_refresh: before rendering I need to measure the text so that I know where to cut up the lines for wrapping them. But I realized that most of the time, the text is the same, and the width it wants to fit into is the same—so the results should be the same. So I kept the previous cache and some extra data to convince myself that the text nor the width has changed and only do the calculation again if something has changed. That took the times for that function from ~4.15ms to ~1.40ms.
Then the second thing I did was harder, profiling I saw that now most of the time was spent flattening out a dag or tree, into a flatten ordered list that can be displayed. I had already battled with this function and cached everything involved with this process and thought there wasn't much worth squeezing out of this. But I kept thinking about the invariants and I found a faster way of flattening the tree without even using the caches that I had and brought that process down from 317us to 86us, and so it shouldn't be a bottleneck any longer.
Overall those and other optimizations brought the time down for refreshes from ~4.15ms to ~0.65ms (on a view with 4 columns, each column requires its own refresh), which combined with a ~13ms GDI render time on a 2K monitor gets you under the times needed to achieve 60FPS.
There still might be more work to be done for people on 4K monitors, but hardware acceleration will get most of that 13ms GDI time down. The part in common is the refreshes, those times will have to be paid also but the GPU paths. But for now it is enough to start packaging up for a release because those are way better times than what the current version of Indigrid can do.
15 Nov 2019: GDI drawing (performance)
I'm now fixing all the little details that you have to crawl through the documentation to find to make the boundaries of your code and the operating system's code meet.
For one, I hold on to the same device context for the lifetime of the window using CS_OWNDC for performance reasons. What was coming up in the profiling was the time needed to create the bitmap for double buffering and then to free the bitmap each time you needed it for drawing. So instead I keep the bitmap around so I can use it across WM_PAINTs without needing to create and free the bitmap on each call. This doesn't work if the device context changes each time. The difference is ~11.4ms without the cached bitmap, and ~7.1ms with the cached bitmap.
Great, only since I hold on to the drawing context for the lifetime of the window for the above performance reasons, I can't use WM_PAINT's prolog and epilog functions: BeginPaint and EndPaint—so I have to reproduce their effects: hiding the caret.
I also had date formatting that wasn't matching what Windows is showing, so I implemented those using the Windows way. And so each platform will probably have to have their own date formatting code to match the format that the user is used to seeing, not what the C++ standard defines.
14 Nov 2019: Font kerning (feature)
Drawing text via ExtTextOut or PolyTextOut doesn't seem to do kerning and Indigrid never had proper kerning and I never noticed until now. But now that I know what to look for, it is very noticable.
Kerning is the spacing between letters, and a font designer will create a list of exceptions to how much space should go between certain characters if when they are next to each others, they don't look right with the default spacing defined across the entire font.
I didn't look into how to force Windows to use the font's kerning table for these exceptions and instead read it myself and look up pairs from it when I'm measuring and drawing text. It took the speed from ~500 nanoseconds, to ~1,150 nanoseconds but that is still an easy tradeoff to make. The code is still ~4x faster than it is in the current version, and it produces better text.
13 Nov 2019: GDI text metrics (bug fixes)
For whatever reason, PolyTextOut wasn't rendering some unicode characters with the same level of precision as ExtTextOut, so I switched back to using ExtTextOut. I still kept some of the speed performance since I still batch up text draw calls by their attributes and only switch device context objects when I get to the next batch with different attributes.
Another detail was when creating the fonts, I would cache the character widths using GetCharABCWidths, only this would give narrow results for some unicode characters—so I rely on GetTextExtentExPoint's alpDx parameter to get the me widths of the characters.
I don't envy the Microsoft programmers that have to maintain these functions, they are complicated and touching anything would break a lot of programs.
I'm thinking I will now be conservative of the calls that I make to Windows, and then cache everything myself so that I don't have to continually ask Windows again for the information.
10 Nov 2019: Replacing slow GDI functions (performance)
Now that I have OpenGL text rendering, I wanted to get GDI's functionality back at par since restructuring the code broke some things that were previously working with GDI.
While restoring functionality I replaced my calls to ExtTextOut to PolyTextOut, which is a single syscall that produces the effects of many ExtTextOut calls. Whenever I saw that function, I wouldn't think ExtTexts, I would think something like TextTransform.
But now that I have a more traditional rendering pipeline, I sorted my text draw calls by their attributes so that I could batch them together by selecting the font, pen, and colors that they have in common, and then package them all at once for PolyText.
The drawing times for ExtTextOut is ~10.89ms vs. ~10.21ms for PolyTextOut, giving me a ~6% speed improvement.
I also rewrote the way that I measured the size of text to cache the widths of characters and to calculate the widths myself. The results between asking GDI's GetTextExtentExPoint and my hand-rolled way is ~4 microseconds to ~0.5 microseconds for a ~800% speed improvement.
7 Nov 2019: LCD font rasterization (feature)
FreeType has grayscale font rendering which I was using, but it also had LCD font rendering where it uses 3 different channels of alpha so that it can break an LCD pixel up into 3 vertical bands to squeeze out a little bit more precision in what pixels the stroke of a font lands on. This is important on displays that don't have the DPI resolution to just throw a bunch of pixels at the font to make it look sharp.
And I had a heck of a time getting this to work—it was discouraging. From getting the different channels out of FreeType and into the GPU in a format that I can then blend, and then writing shader code that would blend those channels in a pleasing way.
I hit a wall in how much quality I was able to get on my own using the FreeType + OpenGL route, and I can't tell if I'm just used to Microsoft's ClearType implementation that GDI uses or if the quality of FreeType's rendering isn't there. I haven't seen an example of someone else get good results from it either—but it might be that it is familiarity and that I like ClearType's implementation better.
In retrospect, this didn't take as long as it felt it took me. There was a day when I didn't feel like programming, which is really rare for me. I think I just needed to think about the problem away from the computer, because I wasn't going to solve it without looking at it outside of the technologies I was working in.
Either way, instead of investing more time down the Windows + FreeType + OpenGL route, I will keep the FreeType + OpenGL route for other platforms that need it and upgrade the Windows path to use DirectWrite + Direct2D. At this point writing another rendering backend seems like a walk in the park compared to squeezing out more quality from FreeType.
I also realized that Indigrid never take into account the fonts kerning tables, you can tell most with these pairs: WA, To, or //.
28 Oct 2019: Text metrics work (architecture)
Combining two different ways of showing text—via GDI and via OpenGL—with different text rendering strategies into a single path that handles both wasn't that difficult. But now all the details come out of the differences between them, starting with how they calculate the metrics from the same font.
Through trial and error, reading documentation and code, and adding in some superstitious magic numbers, the text is mostly in the same place.
However the actual rasterization of the fonts is quite different right now still.
The thing that helped the most was tightening the feedback loop so that I can switch renderers with a key command, because the changes are subtle. This work needs to be done if the look is going to match across platforms, and if the look is going to match what gets printed.
25 Oct 2019: Rewrote string formatting library (infrastructure)
Indigrid depended on FormatMessage, Window's version of sprintf with positional arguments. But other platforms don't have FormatMessage, so I rewrote everything using std::fmt, since it is going to be coming into the C++20 standard—making it available to all platforms.
Only it was hard for me to work with. When I would do something wrong I'd have template errors that would take me a really long time to figure out. And my compile times went from ~4 seconds, to ~5.5 seconds just for this one dependency. But I worked through it some months ago, and after all the messages were rewritten using fmt's syntax—I didn't have to do much work with it.
But it became a part that I didn't feel like touching, and that was OK because I didn't touch it much. And so these sleeping giants were left undisturbed.
Then I had to touch the formatting code again for the perf logging code, and immediately I'm met with more template errors and I knew this was an opportunity to do the right thing for the long term, having code you don't feel good about touching is a liability and it is too tempting to just do "one more little change" to push off throwing it out.
I've never written my own sprintf type function before and I was surprised by how easy it was to wrap the positional arguments part and then delegate the actual formatting down to sprintf, with some custom formatters for converting between utf16 and utf8 text, and adding separators to numbers—things that I could never work out how to do with std::fmt. And the performance is better. The only thing I lost was type safety, but you can still pass "incorrect" types to std::fmt and instead of not compiling, it will throw an exception at runtime—which means I never trusted it to be more "type-safe" than sprintf anyways.
I mean I'm sure it is a lovely library, the author has been working on it forever and I assume I will run into subtleties down the line that std::fmt handles, but I'm still happy with my tradeoff. I understand my code, and can maintenain it going forward.
Compile times are down to ~3.5 seconds—which is important to for making iterations immediate, anything to tighten up your feedback cycle will help your creativity as it is less painful to try out different things.
24 Oct 2019: GDI text perf work (infrastructure)
During the migration, some paths of the text drawing code became slow and it took some work to figure out exactly what was happening. Eventually I localized it to an area that I'm going to rewrite anyways—and so I rewrote it and got the previous performance back.
21 Oct 2019: Rewrote perf code (infrastructure)
As part of porting code from being tied to Windows, to being platform-independent—I had removed the old code use to measure performance. It is a real simple system that just produces a log of how long selected parts of the system are taking to execute.
But I like it because it is easy for me to compare different algorithms, different data access patterns, or different API calls against each other and more deterministically rank them against each other.
20 Oct 2019: Build 26 (bug fixes)
Build 26 was a weird release, there was a bug introduced from build 22 that was reported that I couldn't reproduce. Once I got the crash report and saw that it wasn't frozen—but waiting—I knew it was a problem with the worker threads.
I also personally saw that resizing was very broken as I was writing the changelog, and no one reported it. It wasn't hard to fix, and I need to rethink how I go about testing new versions to prevent things like this from slipping through. The data layer has many checks to ensure your data is protected and accessable, but the operations for interacting with the data via the interface don't have checks on them. I want to think of something to ensure a consistent experience. I want a positive association with upgrading—new features and performance, not breaking things that were previously working.
18 Oct 2019: Build 25 (bug fixes)
Build 24 introduced a problem with window resizing that I didn't notice until a user informed me about it 17 Oct 2019 and I released the new version with the fix on 18 Oct 2019.
There was also a rare bug that had been previously reported, but that I wasn't able to reproduce involving keyframes—but that I was able to reproduce. When pushing enter, if the change requests a keyframe (every 200 changes) and you hit enter again during that window, it would crash. Keyframes are necessary for performance to be consistent no matter how many changes your database has—it prevents things from getting slower over time.
14 Oct 2019: OpenGL fonts (feature)
Font work was written for the OpenGL path, which is the slowest part of GDI code.
7 Oct 2019: Renderer agnostic paths (architecture)
Existing code for doing the graphics was extracted and then shared amongst GDI and OpenGL paths.